For the last two years I've been building AI into everything. A phone-based assistant that takes work orders for a company managing tens of thousands of buildings. A suite of consumer apps covering everything from study help to a farming advisor in Hindi and Punjabi. Internal tools that keep entire teams in sync.
Some of it has been a joy. Some of it has taught me lessons the hard way — usually at midnight, usually in production. Here's what I've come to believe, organized not as a checklist but as the handful of truths that keep proving themselves no matter what I build.
The model was never the hard part
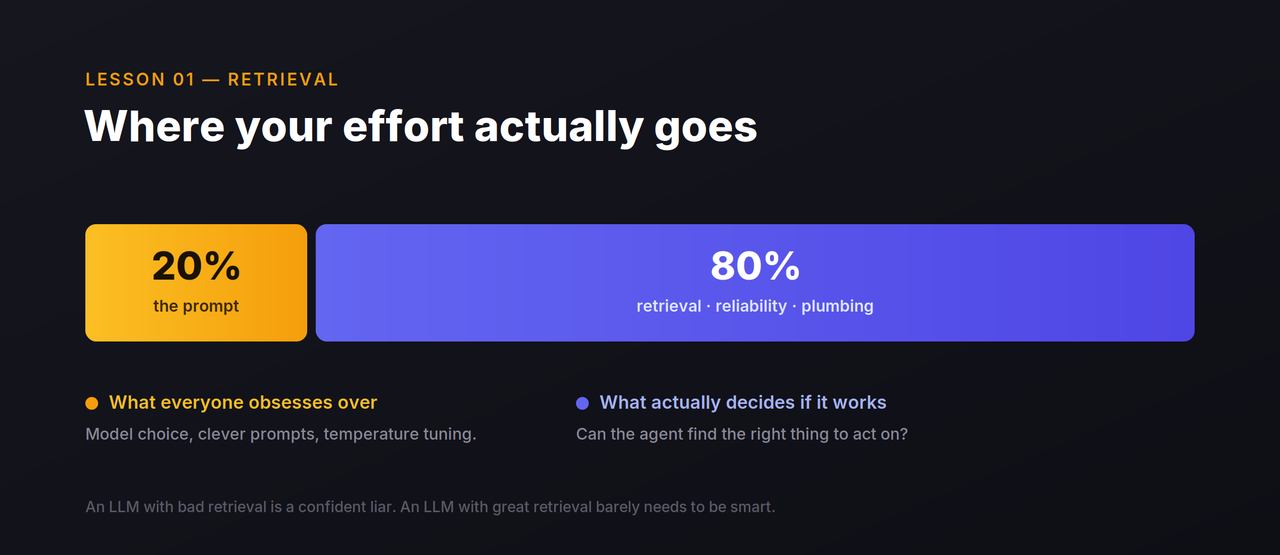
This is the one that took me longest to accept, because the entire industry points the other way. We argue about which model, which prompt, which temperature. Meanwhile, the thing that actually determines whether an agent is useful is almost boring: can it find the right information to act on?
I felt this acutely building a voice assistant that had to pin down one specific building out of tens of thousands, from a caller half-remembering an address on a noisy line. My early version leaned on fuzzy text matching. It demoed beautifully and failed in the field constantly — one vague phrase would match dozens of locations across the country. The fix wasn't a smarter model or a cleverer prompt. It was rebuilding the lookup on a real search engine, with proper indexing and ranking that understood what an address actually is.
That single change improved accuracy more than anything I ever did to the prompt.
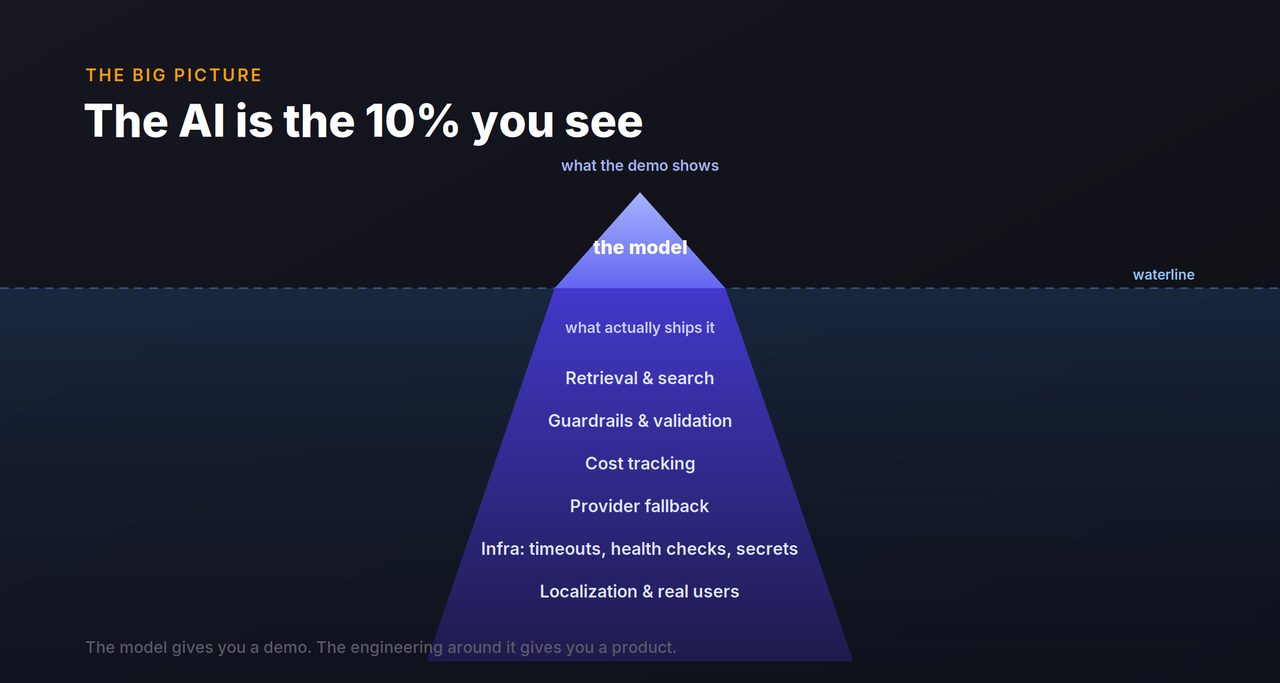
Everything downstream of the model wants to break
Once you accept that the model is the easy 10%, the rest of the iceberg comes into view — and it's the part that sinks you.
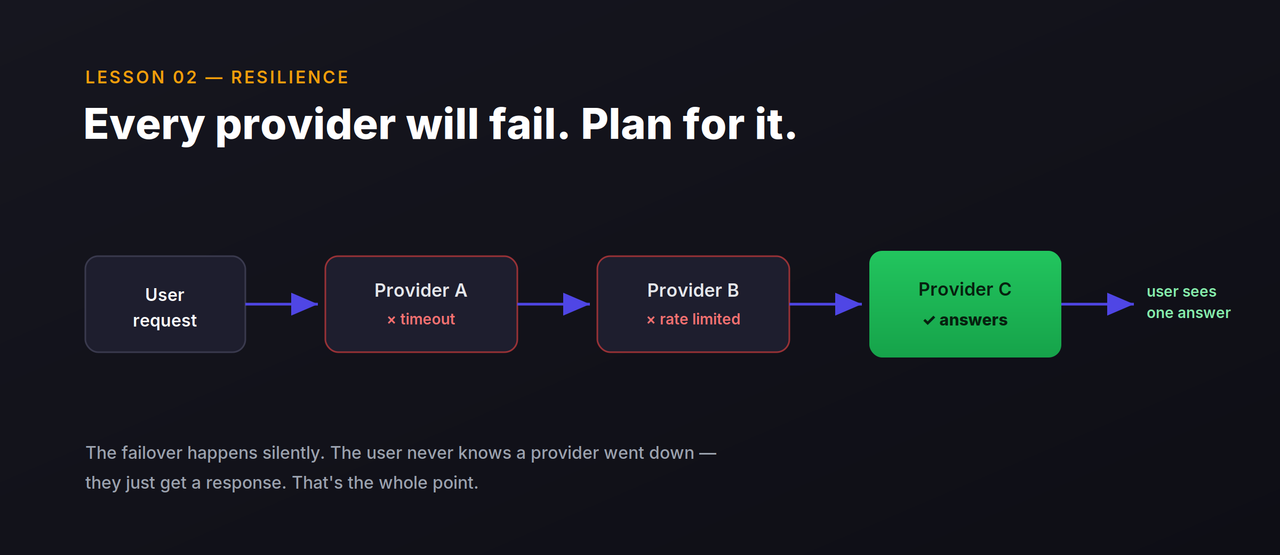
Providers fail, and they fail at the worst time
The first time my upstream LLM provider had an outage during business hours, my consumer apps went dark and one-star reviews started landing within minutes. Users don't care that a third party is down; they care that your thing is broken. So now everything I build runs a fallback chain — the primary provider times out or rate-limits, and the request silently rolls to the next one. The user never knows there was a problem. Treat every single provider as something that will go down, because eventually it does.
Voice breaks in ways text never does
If you've only built chat interfaces, voice will humble you fast. My phone assistant kept hearing "report" as "reboot." Callers would pause to think and the transcriber would emit an empty string, which my code read as a hang-up — so the agent would politely end the call on someone mid-thought. And structured output that worked perfectly in text mode silently stopped appearing in voice mode, because the model behaves differently when it thinks it's talking rather than writing. Voice is not text with a microphone attached.
The infrastructure betrays you before the AI does
One of my worst outages had nothing to do with the model: a slow external search API was blocking the platform's health check, so the host decided my app was dead and killed it. A cascading failure triggered by a dependency three layers removed from anything "AI." Most of your incidents won't be hallucinations — they'll be timeouts, missing secrets, a wrong file path in a container, a health check that's too strict. Respect the plumbing.
The agent will lie, so build the brakes early
There's a particular kind of dread in watching an AI state something completely false, with total confidence, to a paying customer. Early on I treated guardrails as a "later" problem. That was a mistake — because by the time you notice you need them, the agent has already said something embarrassing or expensive.
Now I build the guardrails alongside the agent: validation on what it's allowed to claim, hard checks before any action that touches real data, and explicit refusals when it doesn't actually know. An agent that says "I'm not sure — let me get you a human" is far more valuable than one that confidently invents an answer. Your users can't tell confidence from correctness. Your guardrails have to.
Real users are not the user in your head
Two things about real users reshaped how I build.
The first is language. The farming app I work on serves people across India. English-only would have locked out half of them. Supporting Hindi and Punjabi wasn't polish at the end — it was the difference between a product and a tech demo, and it shaped which models I picked and how I prompted them. For most of the world outside a few tech hubs, language is a core product decision, not a localization checkbox.
The second is money. AI costs real money on every call — a fundamentally different business than traditional software, where one more user costs almost nothing. I once had cost tracking silently break because a provider switched to versioned model names and my accounting code stopped matching them; the spend continued, the dashboard just went blind. Across my consumer apps I had to design the whole token economy — limits, tiers, validation — before growth, not after. Going "viral" while every free user runs up an unbounded bill isn't a success story. Instrument cost per request, per user, per feature from day one.
What it all comes down to
After two years and more AI products than I can comfortably count, the pattern is clear: the AI is rarely the hard part. Retrieval, reliability, guardrails, cost, infrastructure, and knowing your actual users — these are old engineering problems wearing a shiny new hat. The teams that win at AI aren't the ones with the cleverest prompts. They're the ones who treat their agent like the production system it really is.
Frequently Asked Questions
What is the hardest part of building an AI agent?
Why do AI agents fail in production when they work fine in demos?
What is a provider fallback chain and why do I need one?
How do you keep AI agent costs under control?
Do AI agents really need guardrails?
Is the language an AI agent supports actually important?
Built by people who ship AI, not just talk about it
Everything here came from real products in real users' hands — study tools, a legal advisor, a farming assistant, and more, all powered by the same hard-won engineering. Take a look at what we've built.
⚡ Explore Advanced AI Apps